As you probe into the world of the Semantic Web, you’ll soon discover that ontologies play a vital role in organizing data and knowledge. But have you ever wondered how these ontologies are developed and enhanced? The answer lies in three crucial aspects: modeling, learning, and populating. In this journey, you’ll explore each of these facets in detail, uncovering the collaborative construction of ontologies, the automatic generation of ontologies from data sources, and the instantiation of ontologies with specific instances. By grasping these concepts, you’ll gain a deeper understanding of how ontologies are built and utilized for the Semantic Web.
Key Takeaways:
Modeling: Ontology modeling focuses on creating structured representations of knowledge in a specific domain, involving collaborative construction and developing specific frameworks for particular tasks.
Learning: Ontology learning aims to automatically or semi-automatically generate ontologies from various data sources, using approaches such as machine translation, concept learning, and supervised learning.
Populating: Ontology population involves instantiating the ontology with specific instances or individuals, including event-centric knowledge graphs and information retrieval enhancement, and addressing challenges such as scalability, integration, and interpretability.
While creating a robust and meaningful ontology is a crucial step in organizing data and knowledge for the Semantic Web, it’s important to recognize that ontology modeling is a multifaceted process. At its core, ontology modeling involves creating structured representations of knowledge in a specific domain, which can be used across different applications and systems.
This process involves several key aspects, including collaborative construction and the development of specific frameworks. By understanding these aspects, you can better appreciate the complexity and importance of ontology modeling in the context of the Semantic Web.
Collaborative Construction
Ontological construction is often a collaborative effort, requiring input from multiple experts with diverse knowledge and expertise. Collaborative construction involves supporting the collaborative development of ontologies, allowing multiple experts to contribute their knowledge. This approach ensures that the resulting ontology is comprehensive, accurate, and reflects the collective understanding of the domain.
In practice, collaborative construction may involve using specialized tools and platforms that facilitate collaboration, communication, and knowledge sharing among experts. By leveraging the collective expertise of multiple stakeholders, you can create ontologies that are more robust, reliable, and effective in capturing the nuances of a particular domain.
Specific Frameworks
Frameworks provide a structured approach to ontology development, guiding the creation of ontologies for specific tasks or applications. Developing ontological frameworks for particular tasks, such as decision support and business process modeling, enables you to create targeted and effective ontologies that meet the needs of a specific domain or application.
Frameworks can provide a set of guidelines, principles, and best practices for ontology development, ensuring that the resulting ontology is consistent, coherent, and well-suited to its intended purpose. By using specific frameworks, you can streamline the ontology development process, reduce errors, and increase the overall quality of the resulting ontology.
Specific frameworks can be particularly useful when developing ontologies for complex domains or applications, where a structured approach is important for capturing the intricacies and relationships within the domain. By leveraging these frameworks, you can create ontologies that are better equipped to support decision-making, problem-solving, and knowledge discovery in a particular domain.
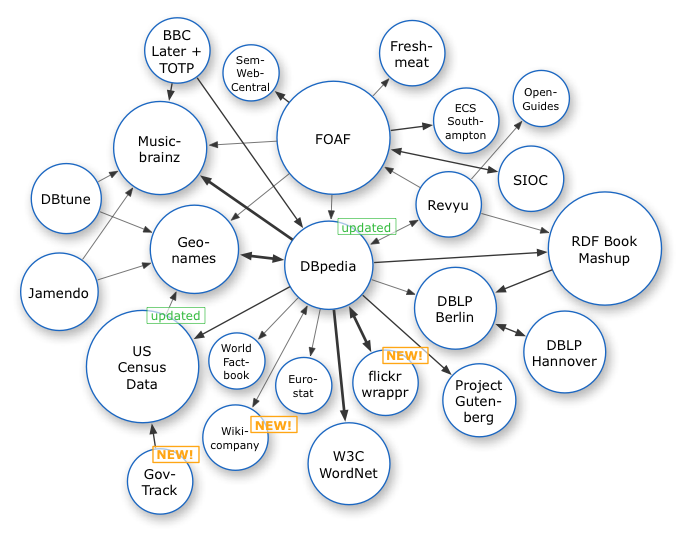
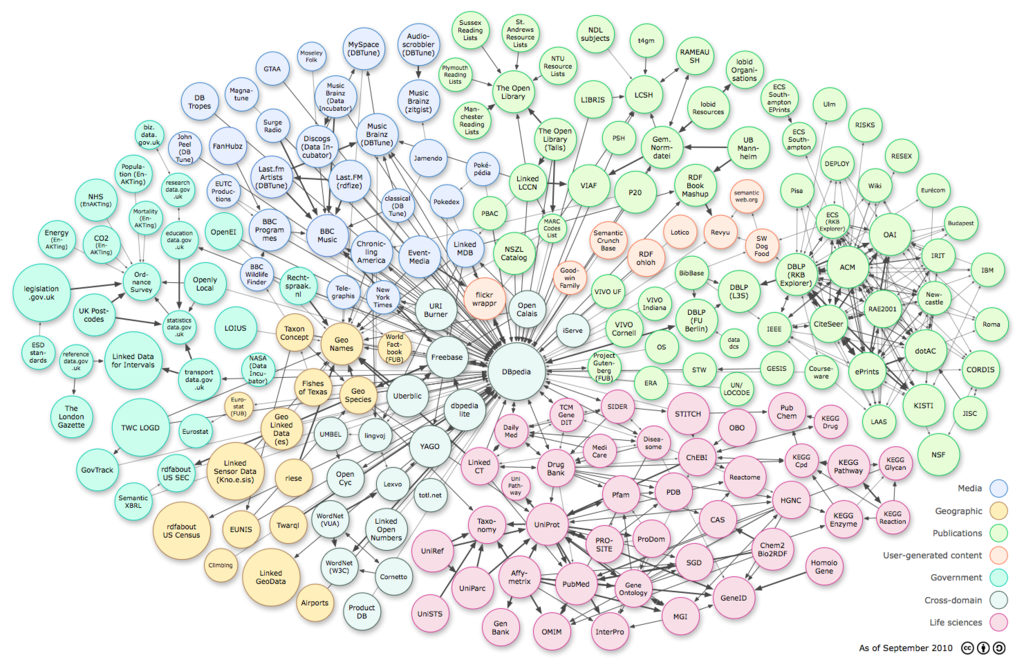
The Semantic Web relies heavily on the formal ontologies that structure underlying data for the purpose of comprehensive and transportable machine understanding.
Maedche, Alexander & Staab, Steffen. (2001). Learning Ontologies for the Semantic Web.1
Ontology Learning
If you’re looking to automatically or semi-automatically generate ontologies from various data sources, particularly textual content, then ontology learning is the way to go.
Ontology learning involves a range of approaches, each with its own strengths and weaknesses. By understanding these approaches, you can determine which one best suits your needs.
Machine Translation Approach
Approaching ontology learning as a neural machine translation task allows you to treat the learning of expressive ontological axioms from natural language sentences in a unique way. This approach leverages the power of machine learning to translate natural language into formal ontological representations.
This method has shown promise in generating high-quality ontologies from large amounts of textual data. By fine-tuning neural machine translation models on specific domains, you can adapt this approach to suit your particular needs.
Concept Learning
To develop methods for learning concept descriptions for ontology enrichment at the terminological level, you’ll need to investigate into the world of concept learning. This approach focuses on refining concept descriptions to better capture the nuances of a particular domain.
By learning concept descriptions, you can enrich your ontology with more accurate and detailed information. This, in turn, enables more effective reasoning and inference capabilities.
Plus, concept learning allows you to tackle complex domains with ease, making it an imperative tool in your ontology learning toolkit.
Supervised Learning
An alternative approach to ontology learning is supervised learning, which uses positive and negative training examples from existing ontologies to approximate intensional definitions in Description Logics (DLs).
By leveraging the power of supervised learning, you can train models to recognize patterns in existing ontologies and generate new ones that are consistent with the training data.
It’s worth noting that supervised learning requires a significant amount of high-quality training data, which can be time-consuming to prepare.
Notable Algorithms for Concept Learning
Notable algorithms for concept learning include DL-FOIL and CELOE, which use refinement operators to specialize partial solutions and cover training examples correctly.
These algorithms have shown impressive results in generating accurate concept descriptions and are worth exploring in more detail.
With the right algorithm, you can unlock the full potential of concept learning and create high-quality ontologies with ease.
Ontology Population
After creating a well-structured ontology through modeling and learning, the next step is to populate it with specific instances or individuals. This process involves instantiating the ontology with real-world data, making it possible to reason about and draw conclusions from the knowledge represented.
Event-Centric Knowledge Graphs
For creating knowledge graphs from natural language texts, focusing on events and their relationships is a crucial aspect of ontology population. This approach enables the extraction of meaningful information from unstructured data, such as news articles or social media posts, and represents it in a structured format. By doing so, you can analyze and query the graph to gain insights into the relationships between events, entities, and concepts.
Furthermore, event-centric knowledge graphs can be used in various applications, such as information retrieval, question-answering, and decision support systems. By populating the ontology with event-centric knowledge graphs, you can create a powerful tool for analyzing and understanding complex systems and relationships.
Information Retrieval Enhancement
To improve information retrieval tasks, populated ontologies can play a vital role. By using ontologies to provide a semantic layer on top of traditional keyword-based search, you can enhance the accuracy and relevance of search results. This is achieved by leveraging the conceptual relationships and hierarchies defined in the ontology to disambiguate search terms and retrieve more relevant documents.
In addition, populated ontologies can facilitate more advanced search functionality, such as semantic search, faceted search, and query expansion. By incorporating domain-specific knowledge and relationships into the search process, you can provide users with more precise and informative results.
Plus, the use of populated ontologies in information retrieval can also enable the development of more sophisticated search interfaces, such as natural language question-answering systems or recommender systems. By tapping into the wealth of knowledge represented in the ontology, you can create more intelligent and user-friendly search systems that provide better support for decision-making and knowledge discovery.
Applications of Ontologies in the Semantic Web
Many applications of ontologies in the Semantic Web have been explored, and they have shown great potential in various domains. In this section, we will discuss some of the most promising applications of ontologies.
Decision Support Systems
The use of ontologies in decision support systems (DSS) has been gaining popularity in recent years. The idea is to use ontologies to represent knowledge in a specific domain, and then use this knowledge to support decision-making. For instance, an ontology-based DSS can be used in healthcare to help doctors diagnose diseases based on patient symptoms and medical knowledge.
The benefits of using ontologies in DSS are numerous. They provide a shared understanding of the domain, enable knowledge reuse, and facilitate the integration of different data sources. Moreover, ontologies can help to reduce the complexity of decision-making by providing a structured representation of knowledge.
Business Process Modelling
For business process modelling, ontologies play a crucial role in providing a common understanding of business processes and their components. By using ontologies, businesses can model their processes in a more structured and standardized way, which enables better communication and collaboration among stakeholders.
Systems that use ontologies for business process modeling can analyze and improve business processes more effectively. They can identify inefficiencies, suggest improvements, and provide a framework for process re-engineering. Furthermore, ontologies can facilitate the integration of different systems and applications, enabling seamless communication and data exchange.
Ontologies can also be used to model business rules and constraints, which is important for ensuring compliance with regulatory requirements and industry standards. By using ontologies, businesses can create a knowledge base of their processes and rules, which can be reused across different applications and systems.
Challenges in Ontology Development
To develop high-quality ontologies for the Semantic Web, you need to overcome several challenges that can hinder the effectiveness of your ontology development process.
Scalability
With the rapid growth of the Web of Data, scalability has become a major concern in ontology development. As the size of the data increases, traditional symbolic methods may become inefficient, and numeric-based approaches may be more suitable. However, these approaches also have their limitations, and you need to find a balance between the two.
For instance, when dealing with large datasets, you may need to use distributed computing techniques to speed up the processing time. Additionally, you can leverage cloud computing services to scale up your ontology development process.
Integration of Symbol-based and Numeric-based Approaches
Challenges arise when trying to integrate traditional symbol-based methods with newer numeric-based approaches. These two paradigms have different strengths and weaknesses, and combining them effectively can be difficult.
Ontology learning, for example, can benefit from the integration of symbolic and numeric approaches. Symbolic methods can provide a deeper understanding of the domain, while numeric methods can handle large datasets efficiently. By combining these approaches, you can leverage the strengths of both and develop more accurate and efficient ontology learning algorithms.
Moreover, integrating symbolic and numeric approaches can also enable the development of more robust and flexible ontologies that can handle complex data and uncertainty.
Handling Incompleteness and Inconsistency
Ontology development often involves dealing with incomplete, noisy, and sometimes inconsistent data. This can lead to inconsistencies and errors in the ontology, which can negatively impact its overall quality.
Ontology engineers need to develop methods to handle these issues effectively. For instance, you can use data preprocessing techniques to clean and normalize the data before using it to populate the ontology.
Another approach is to use uncertainty reasoning techniques to handle incomplete and inconsistent data. These techniques can help you to reason about the uncertainty in the data and develop more robust ontologies that can handle ambiguity and vagueness.
Interpretability
Any machine learning model used in ontology development should be interpretable and transparent. This is particularly important in concept learning tasks, where the model’s output needs to be understandable by humans.
You need to balance the effectiveness of machine learning models with the need for interpretability. This can be achieved by using techniques such as feature importance analysis, model explainability, and visualization.
Scalability is also crucial in ensuring the interpretability of machine learning models. As the size of the data increases, the model’s complexity also increases, making it harder to interpret. By developing scalable machine learning models, you can ensure that the model remains interpretable even with large datasets.
Future Research Directions
Now that we have explored the current state of modeling, learning, and populating ontologies for the Semantic Web, it is necessary to look ahead and identify areas that require further research and development.
Addressing Current Challenges
For instance, you may want to investigate ways to tackle the scalability issue, which is becoming increasingly pressing as the Web of Data continues to grow. This could involve developing novel numeric-based methods that can handle large datasets efficiently. Furthermore, you may explore approaches to integrate symbol-based and numeric-based methods, allowing us to leverage the strengths of both paradigms.
Additionally, you may focus on developing techniques to handle incompleteness and inconsistency in ontologies, which is a pervasive problem in many domains. This could involve designing algorithms that can detect and resolve inconsistencies, or developing methods to reason with incomplete information.
Improving Automation and Efficiency
Challenges in ontology development can be alleviated by improving the automation and efficiency of the processes involved. You may investigate ways to automate the ontology modeling process, for example, by developing tools that can assist in the collaborative construction of ontologies. Alternatively, you may explore approaches to automate the ontology learning process, such as using machine translation techniques to generate ontological axioms from natural language sentences.
It is crucial to note that improving automation and efficiency will require significant advances in areas such as concept learning, where the goal is to develop methods that can learn concept descriptions from data. This, in turn, will depend on the development of more sophisticated refinement operators and techniques for approximating intensional definitions in Description Logics (DLs).
To wrap up
So, as you’ve seen, the development and enhancement of ontologies for the Semantic Web is a multifaceted process that involves modelling, learning, and populating. By creating structured representations of knowledge, automatically generating ontologies from data sources, and instantiating them with specific instances, you can unlock the full potential of the Semantic Web. However, you’ve also seen that there are challenges to be addressed, such as scalability, integration of approaches, handling incompleteness and inconsistency, and interpretability.
As you move forward in your exploration of ontologies for the Semantic Web, remember that the key to success lies in balancing the strengths of different approaches and addressing the challenges that arise. By doing so, you’ll be contributing to the creation of a more efficient, effective, and meaningful web of data that can revolutionize the way we access and utilize knowledge. The future of ontology development for the Semantic Web is bright, and with your involvement, it can become even brighter.
FAQ
Q: What is the primary goal of ontology modeling in the context of the Semantic Web?
A: The primary goal of ontology modeling is to create a shared and common understanding of a domain that can be used across different applications and systems. This involves collaborative construction and developing specific frameworks for particular tasks, such as decision support and business process modeling.
Q: What are some key approaches to ontology learning from textual content?
A: Some key approaches to ontology learning include the machine translation approach, concept learning, and supervised learning. These approaches aim to automatically or semi-automatically generate ontologies from various data sources, particularly textual content. Notable algorithms for concept learning include DL-FOIL and CELOE, which use refinement operators to specialize partial solutions and cover training examples correctly.
Q: What is the significance of ontology population in the context of the Semantic Web?
A: Ontology population involves instantiating the ontology with specific instances or individuals. This process is crucial for creating knowledge graphs from natural language texts, focusing on events and their relationships, and improving information retrieval tasks. Populated ontologies can enhance the effectiveness of various applications and systems on the Semantic Web.
Q: What are some of the significant challenges in ontology development for the Semantic Web?
A: Some significant challenges in ontology development include scalability, integrating symbol-based and numeric-based approaches, handling incompleteness and inconsistency, and ensuring interpretability. Addressing these challenges is crucial for further improving the automation and efficiency of ontology development processes for the Semantic Web.
Q: What are some potential future research directions in ontology development for the Semantic Web?
A: Future research directions may focus on addressing the existing challenges, such as scalability, integration, and interpretability, and further improving the automation and efficiency of ontology development processes. This could involve developing new methods and approaches that combine the strengths of traditional symbol-based methods with newer numeric-based approaches and leveraging machine learning and other advanced technologies to enhance ontology development for the Semantic Web.
Ken Peluso is an entrepreneur with multiple online businesses and author of Mastering Schema Markup: A Strategic Guide to Search Engine Success. Coder, blogger, content curator.